투명한 기부를 하고싶다면 이 링크로 와보세요! 🥰 (클릭!)
바이낸스(₿) 수수료 평생 20% 할인받는 링크로 가입하기! 🔥 (클릭!)
오 이런 포스트 제목 좀 뻔한데?
아무튼, 개인적인 이유로 사람들이 별로 안 읽은 논문을 흥미롭게 읽어서 발표해야 하는 일이 생겨서 StarGAN V2 논문을 읽게 되었다. 포스트 작성일 기준 3일전에 발표된 논문이니깐 다른 사람들이 그닥 많이 정보를 올려놓지는 않았으리가 믿으면서.. :)
윤제형이 처음 StarGAN 발표할 때만 해도 ㅇ우오아아.. 대박이다 했던게 엊그제같은데 벌써 V2가 나오고 그 사이에 다양한 논문들이 나오다니 지이이인짜 시간이 너무 빠르다. 후... 난 제발 취업좀;; 취업성공!
StarGAN v2 , 어디에 써?
StarGANv2 는 우선 새로운 이미지를 생성하는 GAN을 기반으로 만들어졌으며, 그렇기에 기존에 없던 새로운 이미지를 만들어내는 '생성모델'이다. 그리고 StarGAN v2는 단순히 그럴듯한 이미지만을 생성해내는게 것이 아니라 다양한 도메인에 대해서 image-to-image translation을 가능하게 한다. 또한 다양한 도메인에 대한 style transfer을 위해서 다양한 생성기 등이 필요한 것이 아니라 단일 생성기와 단일 스타일 인코더 등을 사용하여 여러 도메인(주제)에 대한 스타일 변환을 가능하게 한다는 점이 다른 점이다. 특히, 이전 버전과 다르게 사진으로부터 새로운 스타일을 추출하여 새로운 사진에 입힐 수 있다는 점 또한 매력적인 부분이다.
관련 연구들.
우선, Image-to-Image Translation task같은 경우에는 기존에 잘 알려진 Pix2Pix, CycleGAN, DiscoGAN 등이 있다.
이 연구들은 결과적으로 특정 도메인 A와 B 사이에서 A에 해당하는 이미지를 B에 해당하는 이미지로 변환시켜주는 Generator을 만드는 연구를 한다. 그리고 이 과정을 A->B로 바꾸고 B->A로 바꾸는 두 과정을 동시에 진행하며 한 쌍의 Generator과 Discriminator을 만들게 된다.
그리고 이를 개선한 논문, starGANv1 이 있다.
StarGAN의 경우 기존의 multi-domain image translation tasks에서 비효율적이던 문제를 해결하였다. 그 이전에 존재하던 모델들은 N개의 모델들을 서로 다른 domain의 이미지로 변환을 하고 싶다면 N(N-1)개의 generator가 필요했다.

그렇지만 StarGAN의 경우에는 입/출력의 domain이 고정된 변환을 배우는 것이 아니라, 모델이 이미지와 domain정보를 함께 input으로 받아서 input image를 해당 domain이미지로 translate할 수 있도록 학습 시키는 것이다.
이 논문의 모델 구성을 식으로 표현하자면 생성기 G는 target domain label c를 통해 input x를 output y로 변환하는 G(x,c)->y를 수행해야 한다.
또한 discriminator은 real image인지, fake image인지에 대해 알아내는 것 뿐만 아니라 어떤 class인지 domain classification까지 같이 수행해야 한다.

다만 시나리오는,
D(real) -> real / fake + classification
D(fake) -> real / fake
G(real image , target domain label) -> fake image
G(fake image , original domain label) -> reconstructed image
를 수행한다.
loss는 c를 target class c`을 real class라고 할 때
1. GAN 에서 사용하는 adversarial loss를 적용한다. real/fake discriminator를 사용하여 G/D에 대해 : log(D(x)) + log(1-D(G(x,c)))
2. domain을 맞추는 classification loss를 classification discriminator을 사용하여 G에 대해 : -log(D(c|G(x,c))) / D에 대해 -log(D(c`|x))
3. 기존 이미지를 얼마나 잘 복원하는지에 대한 평가를 위하여 reconstruction image loss G에 대해: ||x-G(G(x,c),c`)||_1 으로 loss를 정의한다.
이 때, target domain을 어떻게 넣어주냐면 image r g b 채널 뒤에 class channel을 넣어주어서 해당 class field를 전부 1로 바꿔준다.
그래서 이번엔 어떤 모델을 제안했나?
기존 stargan의 경우 각 도메인에 대한 결정을 직접 한번에 하나씩 해야 했지만 이번 stargan v2에서는 두가지 주요한 변경점이 있다. 어떤 도메인의 하나의 이미지를 타겟 도메인의 여러 다양한 이미지들로 변경했다는 점. 그리고 동시에 여러 타겟 도메인을 목표로 할 수 있게 되었다는 점이다. 기존 StarGAN의 경우 데이터 분포에 대한 다양한 특성을 반영하지 못했다. 따라서 generator은 one-hot vector등의 고정된 label만을 입력으로 가질 수 있었다. 그렇지만 이제는 특정 도메인에 대한 다양한 style'들' 을 표현할 수 있게 만들었다. (이 부분이 개인적으로 처음에는 살짝 헷갈렸는데, 특정 도메인이라는 표현은 '남자' , '여자' 를 의미하고 여러 스타일들은 '금발' , '얼굴의 각도' 등을 의미하는 것이었다.)
X와 Y를 이미지의 집합 , 가능한 도메인들이라고 각각 놓자.
목적은 single generator G가 이미지 x와 연관되어 있는 임의의 domain y에 대응하는 다양한 이미지들을 생성하는 것이다. 우리는 도메인-특정적인 '학습된 style space의 style vector'를 만들어내고, G에게는 특정 style vector을 반영하게 만들었다.

Generator(a) : 우리의 생성기 G는 입력 이미지 x를 mapping network F와 style encoder E로부터 나온 output 도메인 s를 반영하는 이미지 G(x,s)로 변경한다. G에 s를 넣기 위해서 adaptive instance normalization을 사용했다고 한다.
* adaptive instance normalization이란?
Generator의 feature statistics도 generated image의 스타일을 컨트롤 할 수 있다.
AdaIN은 content input x 와 style input y를 입력으로 받고, x가 y의 channel-wise 평균과 분산과 매치가 되게 대입한다.

Instance normalization에서 평균과 분산 파라미터를 바꿈으로 인해서 스타일이 바뀐다는 것은 Conditional instance normalization 논문에서 이미 보여준 바 있다.

Training중에 스타일이미지는 그의 인덱스 s와 함께 선택되는데 이것은 1~S사이의 고정된 숫자로부터 선택된다.
놀랍게도 instance normalization의 아핀 파라미터 감마 베타만 바꿀 뿐인데도 불구하고 같은 네트워크일지라도 완전히 다른 스타일을 생성해내는 것을 볼 수 있다.
이 때, 도메인 y의 특징을 뽑아낼 수 있도록 스타일 s를 합성했기 때문에 우리는 더 이상 y를 G에 넣어 줄 필요가 없다는 것을 기억하자.
Mapping network (b) : 도메인 y와 latent code z가 주어질 경우 mapping network F는 style code

를 만들어 낸다. 이때 F_y( . )는 도메인 y에 대응되는 F를 의미한다. F는 가능한 모든 도메인의 style code를 제공하기 위해 여러 출력 branch들과 함께 MLP(멀티 레이어 퍼셉트론)으로 이루어져 있다. F는 z와 y를 샘플링하여 다양한 style code를 생성한다. 우리의 multi-task architecture 은 F가 모든 도메인에 대해 스타일 표현을 효율적으로 할 수 있게 만들었다.
Style encoder (c) : 이미지 x와 그 대응되는 도메인 y에 대해, 우리의 인코더 E는

를 뽑아낸다. F와 비슷하게 E도 multi-task learning setup에 강점이 있다. G가 레퍼런스 이미지 x에 대한 style을 반영하여 생성할 수 있게 해준다.
Discriminator (d) : Discriminator D는 여러 output branches를 가지고 있는 multitask discriminator 이다. 각 브렌치 D_y는 해당 y도메인의 이미지인지 아니면 G(x,s)를 통해 만들어진 fake image인지를 판별한다.
Objective
* 수식 이미지 붙여넣기가 왜이렇게 안예쁘냐;;;; 죄송합니다;;
Adversarial objective :
학습 공간 latent code z 와 target domain
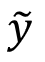
를 랜덤하게 샘플하고 target style code 생성을

로 생성한다. Generator G는

와 이미지 x를 받아서 아웃풋 이미지
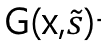
를 adversarial loss

를 통해 학습한다. 이때 D_y는 domain y에 대한 D이다.
Mapping network F는 target domain y 안에서 있을법한 스타일 코드 s를 생성하는 것을 학습하며 G는 s를 통해 타겟 도메인 y와 구분되지 않는 이미지 G(x,s)를 만들어 내는 것을 목적으로 한다.
Style reconstruction :
생성기 G가 스타일 코드 s 를 이미지 G(x,s)를 만듦에 있어서 활용하게 하기 위해서 style reconstruction loss를 도입하였다.

이미지로부터 그 latent code를 mapping할 수 있게 하는 encoder를 적용한 것이다. 단, 단일 인코더 E를 통해서 여러 domain에 대한 다양한 출력을 뽑아냈다는 것이 특별한 점이다. 마지막으로 학습된 인코더 E는 G에게 reference image의 스타일을 반영할 수 있게 만들어준다.
Style diversification :
다양한 style을 생성할 수 있게 하기 위해서 diversity sensitive loss를 추가했다.

이 때 s_1과 s_2는

함수로부터 서로 다른 latent vector z_1과 z_2 에서 생성된 스타일 코드이다.
이 objective에는 optimal point가 없으므로 트레이닝을 시키면서 해당 loss를 linearly decay시켰다.
Preserving source characteristics :
위 Objective 만으로는 이미지

가 본래의 이미지 x에 대한 도메인에 해당하지 않는 속성들 (예를 들어 포즈라던가 하는)을 보존하고 있는지 확신할 수 없다. 따라서 cycle consistency loss를 추가하였다.

이때,

는 input 이미지 x에 대해서 측정된 style code이다. 말로 정리하자면, x를 새로운 스타일 코드로 바꾼 이미지를 원본 스타일 코드로 다시 바꾸어서 원본 이미지와의 차이를 비교한 것이다.
위 논문으로부터 나온 loss들을 model에 대해서 정리하자면
D를 update하는 loss는
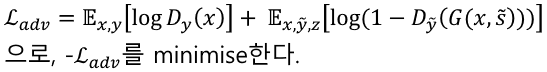
E,F,G를 update하는 loss는

이렇게 하여 결과는

이렇게 나왔다고 한다.
^_^ 갓윤제~짱짱


