투명한 기부를 하고싶다면 이 링크로 와보세요! 🥰 (클릭!)
바이낸스(₿) 수수료 평생 20% 할인받는 링크로 가입하기! 🔥 (클릭!)
모두를 위한 딥러닝 영상을 참고하였음을 밝힙니다.

이번 글에서 다룰 내용이다.

우선, 샘플 데이터셋을 만들어놓자.
y 데이터는 총 3개의 레이블로 되어있다. (one-hot encoding 형식으로 되어있음)

softmax 함수는 다양한 class의 결과에 대한 확률을 output으로 받아볼 때 사용한다. (최종 합이 1이 되어야 한다.)

우선 xw + b는 곱해서 만들어서 결과를 만들어주고, tf.nn.softmax를 통해 softmax 연산을 진행 해 준다.

tfe.Variable을 통해서 행렬을 만들어준다.
tfe (tf eagar mode)는 기존의 graph 모드보다 실시간으로 결과를 손쉽게 받아볼 수 있게 한다.
그 값을 출력해주면 정상적으로 답이 나오는것을 볼 수 있다.
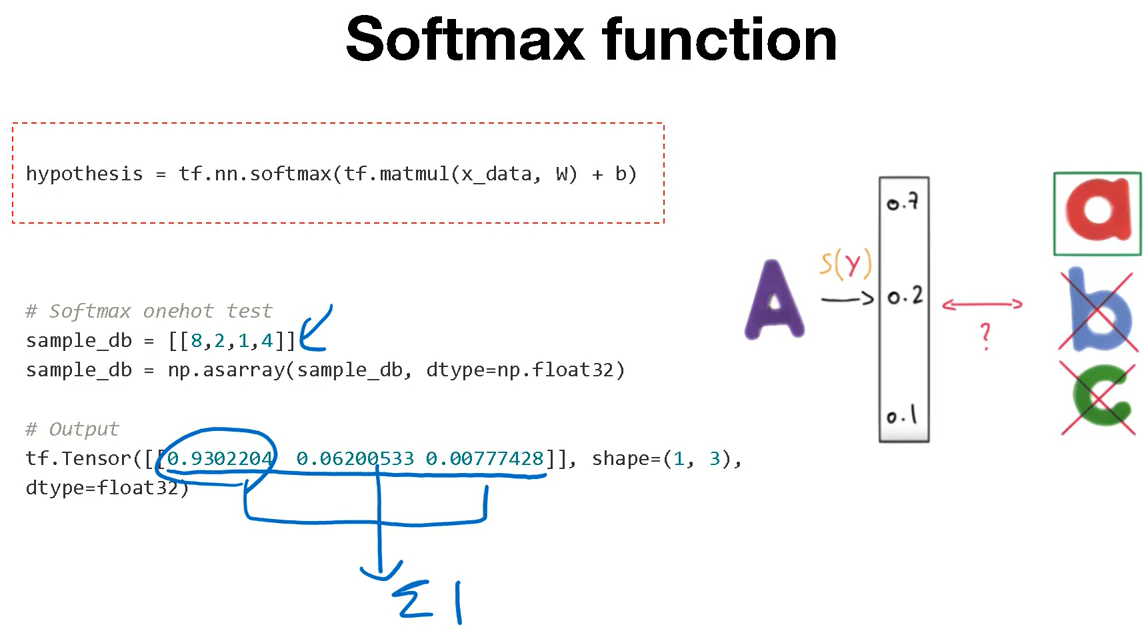
저 위의 값들을 보게 되면 각 class에 대한 확률값이 나오고(총합 = 1) 제일 큰 수가 정답이라 예측하면 된다.

cross entropy cost function을 구하는 코드이다.
(Y * log (Y_hat) 에 대한 계산 결과를 구하는 과정이다.)
그리고 이를 GradientDescentOptimizer(learning_rate=0.1).minimize(cost)를 통해서 최소화 시키는 과정을 진행할 수 있다.


경사하강볍을 활용하여 변수를 optimize 시키는 방법이다.
cost 를 계산하여 출력해보고, grad를 계산하여 출력해본 결과이다.

train을 시키면 정상적으로 loss가 줄어듦을 볼 수 있다.

가장 높은 값을 정답으로 지정하여 (argmax 를 활용하여 구함) 정답 label과 비교를 하면 된다.
출력값을 확인 해 보면 처음의 값에서 가장 높은 값, 두번째에서 가장 높은 값, .... 이런 식으로 그 위치를 저장하여 만든 결과를 print 해보면 정상적으로 나오며 이것은 y_data와 일치하는 것을 볼 수 있고 학습이 정상적으로 이루어졌음을 알 수 있다.

이제 위와 같은 것들을 배워보자.

cross entropy를 구하는 과정에 대해서 설명한다.
1번은 이전 글 내용에서 다뤄보았던 내용이며 2번은 이번에 새로 배워 볼 함수이다.
평균을 구하여 cost를 계산하는 과정이다.
tensorflow는 이 과정을 손쉽게 하기 위하여 hypothesis를 입력으로 받는 것이 아니라 logit 그 자체를 입력으로 받는다.
2번의 접근방법에서 볼 수 있듯, 그저 softmax전의 모델 출력을 넣어주면 그 결과를 가지고 softmax까지 해줘서 정답과의 비교 후 loss 결과를 내준다.

animal classification을 구현해보자.
데이터셋은 동물의 특징을 추출하여 어떤 종인지 예측하는 dataset이다.
다리가 몇개인지 손이 있는지 날개가 있는지 등에 대한 접근방법이다.
기본적으로 numpy 라이브러리를 활용하여서 csv파일을 읽어온다.
y 데이터는 마지막 컬럼이다.

주어진 y값에 대해서 one hot 형태로 바꾸자.
다만 이 결과는 바로 적용시키면 에러가 나는데 그 이유는 input index가 N차원이면 아웃풋은 N+1차원이 된다.
예를 들어 ([0],[3])은 원핫 적용을 하게 되면
[[[1,0,0,0,0,0,0],[0,0,0,1,0,0,0]]]
이렇게 된다.
tf.reshape을 통해서 resize를 해주자.

이제 전반적인 코드를 보자
데이터를 불러오고 x / y 로 나눠준다.
그 후 class 를 지정해주고 onehot + reshape로 y _onehot을 만들어주는 과정이다.

그 후 위와같이 코딩하면 되는데, hypothesis를 거치지 않아도 cost는 구해지지만, hypothesis를 굳이 코딩한 이유는 나중에 prediction을 하기 위해서이다.

gradient function의 경우는 x와 y를 통해서 cost를 계산 해 주고, 이때의 grads를 구해서 넘겨주는 것.
prediction은 tf.argmax를 통해서 예측을 해 준다.
그 후 y값과 pred 값이 일치하는지 계산을 해 주고
마지막에 correct의 비율을 계산하여 accuracy를 계산 해 준다.

그리고 위와 같이 총 training하는 과정을 만들어 줄 수 있다.
잘 학습이 된다.
배운 함수들 정리
tf.argmax(tensor, dimension)
tf.nn.softmax(tensor)
tf.nn.softmax_cross_entropy_with_logits_v2(logit tensor, labels)
tf.reduce_mean(tensor)
tf.onehot(tensor , classnum)
tf.reshape(tensor, [shape])



