투명한 기부를 하고싶다면 이 링크로 와보세요! 🥰 (클릭!)
바이낸스(₿) 수수료 평생 20% 할인받는 링크로 가입하기! 🔥 (클릭!)
요번에 AAAI에 올라간 하이퍼커넥트의 '보이지 않는 타겟의 Identity를 보존하며 몇장의 얼굴 사진만으로 얼굴을 재연'하는 논문이다.
기존의 방법들의 경우, (특히 few-shot setting에서) target 이미지와 source 이미지가 identity가 다를 때에는 얼굴 재연에 있어서 심각한 품질 저하가 일어나고는 했다.

1. identity mismatch를 무시하는 경우에는 새로운 얼굴을 합성했을 때 target이미지와 비슷해지는 결함이 발생한다. (트럼프 얼굴에 다른 표정의 아이린을 target으로 주면 아이린과 닮은 트럼프가 나와버리는 상황 발생 가능)
2. compressed vector representation(AdaIn layer과 같은)의 capacity를 너무 줄일 경우 원본 이미지의 Identity가 너무 줄어들 수 있다.
3. 다양한 포즈를 다룰 때 워핑 작업에서 결함을 발생시킬 수 있다.
이를 해결하고자
image attention block
target feature alignment
landmark transformer
이라는 세 가지 components를 도입하였다.
각각이 무엇인지 천천히 알아보자.

이 아래의 설명들은 위의 그림을 보며 어디에 해당하는지 확인하며 글을 읽도록 하자.
driver x (는 다시 말하면 source x) 정보와 target 이미지 k장을 입력으로 넣어주면 reenacted image가 결과로 나오는 구조이다.
Preprocessor로써 사용한 landmark transformer은 3d landmark detector이다.
아래 논문을 바탕으로 제작했다고 한다.
[Bulat and Tzimiropoulos 2017] Bulat, A., and Tzimiropoulos, G. 2017.
How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks).
In Proceedings of the International Conference on Computer Vision.
그렇게 아래 image로부터 얼굴의 keypoint를 추출하여 randmark image로 바꾸는 과정을 거친다.

Driver encoder(source encoder)의 경우 포즈와 표정 정보를 입력 받아 driver feature map z_x를 만든다.

Target encoder의 경우 U-Net 구조를 채택하였고, target input의 스타일 정보를 추출하여 워핑된 target feature map S_hat과 함께 target feature map z_y 를 생성해낸다.

Blender 는 mixed feature map z_xy 를 생성해내기 위해서 driver feature map z_x 와 target feature map Z_y = [(z_y)^1, ... , (z_y)^K] 를 입력으로 받는다. 아까 위에서 말한 image attention block 이 바로 blender의 basic building block이다. (image attention block은 아래에서 다시 설명)

Decoder은 비틀어진 S_hat과 z_xy를 입력으로 받아서 새로 재연된 이미지를 생성한다. 디코더는 주어진 target feature alignment를 사용하여 재연된 이미지의 퀄리티를 향상시켜 준다.

Image attention block
기존 연구들의 경우 target의 style을 driver에게 전달하는 경우 target information vector로 driver feature에다 concatenation 하여 합쳐주거나 AdaIN layer을 사용하였다. 그렇지만 공간정보를 무시하고 인코딩을 하면 공간정보가 손실될 수 있다. 또 다양한 target의 이미지들을 전제로 한 통계적인 접근 또한 target의 detail을 잃어버리게 할 수 있다.
이 논문에서는 위와 같은 문제점들을 완화하기 위하여 image attention block을 제시한다. 이 block은 transformer의 encoder-decoder의 구조와 유사한데 driver feature map을 attention query로, target feature map 을 attention attention memory로 사용한다. attention block은 여러 target feature maps(Z_y같은) 를 handling하는 동안 각 feature의 특정 position에 집중한다. (아래 사진의 빨간 박스들)

주어진 driver feature map z_x와 target feature maps Z_y = [(z_y)^1,...(z_y)^K] 가 있을 때
해당 차원은

과

이다.
그리고 위의 식을 가지고

위와 같이 연산하게 된다.
위에서 나온 몇가지 연산을 정리하자면
1. 위의 f는

위와 같은 형식으로 flattening function이다. (-1 , c) 형식으로 faltten해준다.
2. W는 특정 채널 개수로 매핑해주기 위한 linear projection matrices이다.

Projection mapping은 쉽게 보면 위와 같다. 단 위 식에서는 channel을 바꿔주기 위한 과정이므로 단순한 mat mul 과정이라면 h_x * c_x * c_a 행렬을 곱해서 새로운 h_x * h_w * c_a 차원으로 projection 할 수 있겠다. 근데 좀 어색한 것 같다. point-wise conv를 그냥 사용했을 수도 있겠다고 생각했다.
3. P_x와 P_y는 feature map의 좌표를 인코딩하는 sinusoidal (사인파의) 포지셔널 인코딩이다.
마지막으로, output A(Q,K,V)는

그렇다고 한다.
기존의 차원은 flatten되어 있던 상황이었기 떄문에 다시 reshape해주는 것.
(개인적으로는 이 과정이 좀 비효율적이라고 느껴진다)
이 부분이 기존의 transformer 과정과 비교해서 좀 와닿지가 않아서 한번 다시 그림으로 그려봤다.
(개인적인 이해를 위해 그린거라 글씨가 고르지 못해서 죄송함니다..)

Instance norm , residual connection , conv layer이 그 다음에 나오며 그를 통해 feature map z_xy를 만들어낸다. (figure 3 그림 참고)
Target feature alignment
target identity에 대한 결이 고운 (fine-grained) 디테일은 low-level feature을 warpping(워핑)함으로써 얻어질 수 있다.
warping flow map 추정이나 target / driver에 대한 차이를 affine transform matrix로 계산하는 이전 approach와는 다르게, 이 논문은 target feature map을 2단계에 걸쳐 워핑하는 target feature alignment를 제시한다.

1. Target pose normalization
encoder E_y 의 경우 인코딩된 feature maps {S_j}_j=1,....,n_y 는 target의 estimated normalization flow map f_y 와 워핑 함수 tau(FIg4의 (1))를 통해서 아래와 같이 process된다.

뒤따르는 디코더의 Warp-alignment block이 S_hat을 pose-agnostic(포즈에 구애받지 않는)하게 다루게 된다.
2 Driver pose adaptation.
디코더 안의 Warp-alignment block는 이전 block의 u 와

를 입력으로 받는다.
few-shot setting에서는 해상도가 호환이 되는 서로 다른 target 이미지들로부터 얻은 feature maps 를 average 시킨다.

이제 계산된 pose-normalized feature maps를 driver의 pose에 적용시키기 위해서, 이 논문에서는 u를 입력으로 받는 1x1 convolution을 사용하여 driver 의 estimated flow map f_u를 생성했다. (처음엔 이 u가 z_xy이고 그 다음부터는 previous block의 output임을 잊지말자) 그 후 FIg 4의 (2)부분의

를 통해 정렬한다. 그리고 이 결과는 u와 concat된 후 conv 1x1을 통해 합쳐진 후 residual up-sampling block으로 들어가게 된다.

Landmark Transformer
기존의 방법들은 few-shot learning처럼 unseen identities를 예측해야 하는 상황에서는 잘 동작하지 않는다. 게다가 기존의 landmark 를 활용하는 방법들은 labeled된 방법을 사용하고는 했다. 이 한계점들을 극복하기 위해서 landmark-transformer 를 통하여 driver의 얼굴 표현 정보를 임의의 target의 identity로 변환해주는 방법을 제안하고 있다. landmark transformer 는 label되지 않은 사람 얼굴 비디오들을 활용하여 unsupervised 방식으로 학습된다.
Landmark decomposition
서로 다른 identities의 비디오 장면들이 주어졌을 때, x(c,t)를 c번째 비디오의 t번째 frame이라고 표기하고 l(c,t)를 3D facial landmark라고 표기하자. 처음으로 모든 랜드마크를 scale, translation, rotation을 normalizing한 normalized landmark로 바꾸자.

3D morphable(재빨리 변형될 수 있는) models of face (Blanz and Vetter 1999) 에 따라, 논문에서는 normalized landmarks 가 아래와 같이 변형될 수 있다고 가정한다.

이때 l_m은 다른 모든 landmark들을 평균낸 facial landmark geometry 이고 (이해되기로는 그냥 보편적인 얼굴 상? 정도로 이해하면 어떨까 싶다), l_id(c)는 identity c의 landmark geometry 이다.

식으로는 위와같이 표현하는데, 이떄 T_c는 c번째의 비디오의 frame 수이다.
l_exp(c,t)는 t번째 frame의 expression(표정) geometry를 나타낸다.

위와 같이 표현된다. (사실 이항한거 빼고는 특이할 것 없는 식이다..)
target landmark l(c_y,t_y) 와 driver landmark l(c_x,t_x)가 주어졌을 떄, 우리는 다음과 같은 변형을 하고 싶은 것이다.

즉, identity는 target의 것이며 expression은 driver의 것인 것을 바라는 것이다.
만약 c_y가 충분히 주어진다면 l_id(c_y)나 l_exp를 계산할 수 있겠지만, few-shot setting에서는 unseen identity를 두개의 term 만으로 해결하기에는 쉽지 않다.
Landmark disentanglement
few-shot setting에서 identity와 expression geometry를 분리하기 위해서 본 논문에서는 뉴럴 넷에게 linear bases로 coefficients를 예측하게 했다. expression landmarks를 얼굴의 semantic groups로 나누었다. (눈 코 입같은 것들) 그리고 각 그룹에 PCA를 수행하여 training data로부터 expression bases를 추출해냈다.

이때 b_exp,k는 basis를 의미하며 alpha_k는 coefficient를 의미한다.
제안된 뉴럴넷, landmark disentangler M의 경우, image x(c,t)와 landmark l(c,t)가 주어지면 alpha(c,t)를 추정한다. 위의Fig 5에 전체적인 그림이 나와있다.
모델이 학습되고 난 이후에는, identity와 expression geometry는 다음과 같이 계산될 수 있게 된다.

위의 람다_exp 는 예측된 expression의 강도를 조절하는 용도이다.
Fig 5를 보면서 흐름을 보면
ResNet-50을 통해 추출된 image feature과 landmark l(c,t)-l_m이 2-layer MLP에 들어가 아래의 결과 예측한다

그럼 결국, 아래의 수식을 표현하기 위해 필요한 모든 표현 방법이 나타났다.
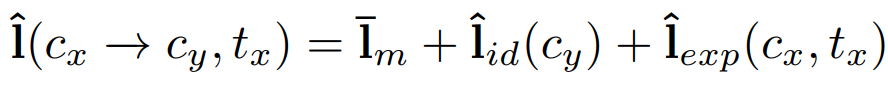
이제 해당 식을 계산하여 driver image를 target image로 변환하는 과정을 계산하면 된다.
실험 결과이다

논문 원본 링크 : https://arxiv.org/pdf/1911.08139.pdf



